
PrivySense: Price Volatility based Sentiments
Estimation from Financial News using Machine
Learning
Raeid Saqur
∗
Department of Computer Science
University of Toronto
Nicole Langballe
Department of Computer Science
University of Toronto
Abstract
As machine learning ascends the peak of computer science zeitgeist, the usage
and experimentation with sentiment analysis using various forms of textual data
seems pervasive. The effect is especially pronounced in formulating securities
trading strategies, due to a plethora of reasons including the relative ease of
implementation and the abundance of academic research suggesting automated
sentiment analysis can be productively used in trading strategies. The source data
for such analyzers ranges a broad spectrum like social media feeds, micro-blogs,
real-time news feeds, ex-post financial data etc. The abstract technique underlying
these analyzers involve supervised learning of sentiment classification where the
classifier is trained on annotated source corpus, and accuracy is measured by
testing how well the classifiers generalizes on unseen test data from the corpus.
Post training, and validation of fitted models, the classifiers are used to execute
trading strategies, and the corresponding returns are compared with appropriate
benchmark returns (for e.g., the S&P500 returns).
In this paper, we introduce a novel technique of using price volatilities to
empirically determine the sentiment in news data, instead of the traditional reverse
approach. We also perform meta sentiment analysis by evaluating the efficacy of
existing sentiment classifiers and the precise definition of sentiment from securities
trading context. We scrutinize the efficacy of using human-annotated sentiment
classification and the tacit assumptions that introduces subjective bias in existing
financial news sentiment classifiers.
1 Introduction
Sentiment analysis of opinion-rich (user-generated or professionally produced) textual data is a broad
topic (e.g. product reviews, political blogs etc.). In this paper, we focus on its impact in the financial
industry - more specifically, automatic sentiment estimation from financial news. Sentiment analysis
is inevitably subjective and therefore varies based on the application and the bias of the reviewers.
However, sentiment analysis for publicly-traded companies is a special case where the market serves
as the judge [
11
]. The reaction to business news is reflected in the price change, along with other
variables concerning price. Typically, sentiment analysis in financial economics refers to the deviation
of market confidence indicators such as stock price and trading volumes [
5
]. This leads to a unique
problem of defining sentiment in financial economics.
∗
I thank Prof. Tom McCurdy (Founder and Academic Director), and Eric Kang (Senior Research Associate)
from Rotman Finance Lab at the University of Toronto, for their kind help with financial data access. All errors
are mine.
In proceedings: Volume 53- Issue 1, 2018 Journal of Financial and Quantitative Analysis
arXiv:1801.00091v2 [q-fin.CP] 21 Feb 2018

Sentiment classification has been primarily researched outside of financial context. Sentiment outside
financial domain is commonly inferred by comparing human-annotated sources or focusing on
customer reviews such as movie reviews, product reviews and other publicly available sources.
Inferring sentiment based on market reaction poses a new challenge as it is varies from the strong
connection between text and reviews captured in previous work [
1
]. The definition of sentiment
within financial news can be measured in several interpretations. The wording of the news can be
analyzed with sentiment based classification used on reviews of products. However, sentiment can
also be inferred through market reactions in terms of stock price, stock price volatility and trade
volumes. All these are indicators of the subjective measure of sentiment. Research indicates that
sentiment varies by domain and tuning sentiment analyzers to the task yields increased results [9].
In this paper, we argued that the definition of ’sentiment’ in the financial domain should be precise
and objective, and should be preferred over subjective human-annotated sentiment classifiers. We
introduce a novel technique of empirically estimating news sentiment for financial news using stock
price volatility instead of the reverse. To our knowledge, this was never attempted before, and has the
potential to produce improved trading strategies and market returns.
2 Related Work
Previous research dating back over 40 years has demonstrated the connection between published
news and market reaction [
9
]. Numerous studies have shown the published news affects the markets
in profound ways, and impacts can be observed from changes in stock price, trade volumes, volatility,
and even future firm earnings [
5
]. Research on the sentiment of financial news further explores this
relationship to market reaction. Koppel and Shtrimberg (2006) established the relationship between
the sentiment of news stories and price changes of a company stock . The impact of social media, and
micro-blogging forums such as Twitter has been connected with stock returns correlating message
volume and trading volume [
15
]. Studies have further explored this linked and predicted stock market
returns from the sentiment on Twitter [
2
]. Investor opinions transmitted through social media have
also been used to predict abnormal stock returns and earnings [4].
Using various forms of sentiment analysis for formulating trading strategies has also been researched.
Zhang and Skiena (2010) used published news sentiment in a market-neutral trading strategy which
provided favorable returns [16]. See Pand, Lee, et al. (2008) for detailed survey in this topic [13].
This paper builds off the work done by Kazemian, Zhao, and Penn (2016) which re-examined the
tactical assumptions behind how sentiment analyzers are evaluated. In this paper, a trading strategy
based on the sentiment of financial news was created and the underlying sentiment analyzer was
examined based on market returns and classifier accuracy compared to human-annotated results.
Results showed that the analyzer with the highest returns had the worst classification accuracy,
showing the need for task-based performance measures. The paper stated that a more precise
definition of news sentiment may lead to improved performance, suggesting the use of stock volatility
as an approach.
3 Method and Materials
3.1 News Data
All news data used were retrieved from Reuters news data collection. First we created sets of 20 stocks
randomly sampled from the universe of stocks that were listed and traded on either the NASDAQ
or NYSE stock exchanges during our ‘evaluation period’: January 1, 2010 to October 30, 2017.
The first set of stocks were roughly evenly weighted collection of 20 small-, mid-, and large-cap
companies in the S&P500 list. The second set of 20 stocks were chosen from a list of ranked top 100
volatile stocks trading in NASDAQ
2
. The reasoning for choosing from multiple sets was to diversify
our news training set corresponding to different levels of average volatility. To elucidate, with the
presumption that stock prices in the S&P500 would fluctuate less to news compared to lower-cap
stocks. Thus, the price volatility would be different for similar news for assets in different classes by
market cap. Combining the two sampled sets calibrated the training set to eliminate this asymmetry.
A news data crawler was implemented to retrieve all Reuters news document belonging to the stocks
2
http://www.marketvolume.com/stocks/mostvolatile.asp
2

during the evaluation period. For our final data set, we coalesced the two sets and sampled 19 stocks
with roughly even weights in terms of news document volumes and set origin. Trying to keep an
even number of news documents for each ticker resulted in a significantly curtailed total number of
documents (as more volatile and lower cap stocks had significantly lower number of news documents
in Reuters data set). In the end, we had approximately 8000 news documents for the final set, which
is comparable to the size used in the Kazemian paper [9], after discounting for duplicates.
Finally, in order to test how well our trained model generalizes on randomly chosen industry news,
we created a separate dataset consisting of only credit card companies during the evaluation period.
Please see Appendix A for details.
3.2 Stock Price Data and Volatility Calculation
We used the Wharton Research Data Services (WRDS) database for collecting all prices data for
our chosen stock sets. The final news dataset was then joined with the prices dataset to add all price
related pertinent columns to our final data (for e.g. ‘prccd’ (closing price)).
Price volatility calculation was an integral precursor for our experiments setup. We incorporated the
‘news impact curve’ which measures how new information is incorporated into volatility estimates -
outlined in the seminal paper by Engle and Ng (1993) into our volatility calculations. The autoregres-
sive conditional heteroskedasticity (ARCH) model, originally introduced by Engle (1982) and its
derivatives are the most popular class of parametric models for news impact curve. The pth order
ARCH model, ARCH(p):
h
t
= ω +
P
X
i=1
α
i
2
t−i
(1)
where
α
1
, ..., α
p
,
ω
are constant parameters. The effect of a return shock i periods ago
(i <= p)
on
current volatility (at time
t
) is governed by
α
i
. We expect that
α
i
< α
j
for
i > j
- meaning, older
news has lesser effect on current volatility. In ARCH(p) model, old news that arrived at the market
more than p periods ago has no effect on current volatility.
In this paper, we have chosen to use a popular generalization of ARCH(p) by Bollerslev (1986) , the
GARCH(p,q) model:
h
t
= ω +
P
X
i=1
α
i
2
t−1
+
q
X
i=1
β
i
h
t−i
(2)
where
α
1
, ..., α
p
,
β
1
, ..., β
p
ω
are constant parameters. Due to its empirical success and wide adoption,
we used the GARCH(1,1) model, where the effect of a return shock on current volatility declines
geometrically over time.
Please see Appendix B for details.
4 Evaluations and Experiments
4.1 Feature Selection: Using TF-IDF, BM25
In order to complete sentiment analysis, feature selection for the collection of words in the news
articles was compared across four methods. The first method was raw term frequency with a binary
term frequency. The next method considered is count of term frequency, which linearly increases
a word vectors weight based on frequency in a document. TF-IDF weight was another method
implemented, TF-IDF is a statistical measure that weights the importance of a word in a document
using term frequency and inverse document frequency [
16
]. TD-IDF increases the weight with rarity
of term in the collection. The weight also increases with the frequency in the document but not
linearly like with count of frequency.The TF-IDF formula implemented was:
w
i
= tf
i
· idtf
i
= tf
i
· log
N
df
i
(3)
where
tf
i
is the term frequency,
idtf
i
is the inverse document frequency, and
N
is the total number
of documents in the collection [
16
].The last method used for feature weighting was BM25 is closely
3

related to TF-IDF, which but has an added relevance score and is based on probabilistic approach
[14]. The formula used for BM25 is:
w
i
= tf
i
· idtf
i
=
(k
1
+ 1) · tf
k
1
((1 − b) + b ·
dl
avgdl
· log
N − df + 0.5
df + 0.5
(4)
where
dl
is the document length,
avgdl
is the average document length in the collection,
k1
and
b
are
parameters set to 1.2 and 0.95 respectively [
16
]. BM25 was implemented in this paper using bm25tf
(term frequency) and bm25Idf (inverse term frequency) as outlined.
4.2 Feature Extraction using NLTK
The feature selection methods detailed in the preceding section had one serious limitation. They
used bag-of-words representation of ‘unigram’ (or simplex) words, which has very limited ability
to capture semantic meaning. We also noticed high-frequency important key words pervasive in
financial documents appearing in both classes (positive and negative) of training data.
To elucidate, consider the simplex or unigram feature words: ‘estimates’, ‘beat’. Now, consider the
following sentences:
• Positive: "Quarterly revenue beat forecasted EPS estimates by $0.25"
• Negative: "The quarterly earnings per share failed to beat analyst estimates."
Here, bag-of-words features representation (even after applying TF-IDF and BM25 filtering) of
features would include the words in both class labels. Thus, to circumvent this issue and improve our
overall model, we explored avenues to extract features that capture semantic meaning.
Scrutinizing academic literature in the NLP domain, we found Su Nam Kim’s (2010) paper on
N-gram based Keyphrase extraction to capture semantic meaning most logical and applicable to our
case.
In order to implement n-gram, we utilized the popular Python NLTK NLP library, which provides
functions for word chunking, stemming, lemmatizing etc. The following Figure 1 shows a high-level
pipeline architecture we implemented for n-gram based feature selection:
Figure 1: High level pipeline for feature extraction.
For part of speeching tagging to tokenized sentences, we had to define regular expression grammar
rules. Figure 2 below shows the grammar definition we used for our experiments. We chose to use
the same rules used by Su Nam et. al. [
10
], and did not attempt tuning rules for optimum results
(falls under
future work
umbrella, discussed in later section). To exemplify, here we only included
4

Figure 2: Regular expression grammar rules for feature selection.
nouns (NN) and adjectives (JJ) for chunks. However, including adverbs (RB) and/or verbs (VB) in
our grammar rules could plausibly improve semantic value captured by chunks.
Additionally, we performed word normalization of all features by using ‘stemmer’ (PorterStemmer)
to stem or convert words to root words, and then ‘lemmatizer’(WordNet) to convert root words to
valid dictionary words - thus ensuring all similar words account for the correct frequency count.
For e.g. ‘performed’, ‘performing’, ‘perform’ are treated as one normalized word ‘perform’ with a
frequency count of 3 instead of three different features with count of 1.
Performing n-gram based feature extraction also allowed us to logically reduce feature dimensions
(by filtering out noisy words). Post extraction, we removed all unigram word features with less than
frequency count of 3 from our features set, thus ensuring our features set contains n-gram terms and
simplex or unigram words with minimum set frequency.
Note: we also did not tune the ‘n’ parameter, i.e. the word sequence count in our n-gram features.
We used minimum ‘2’ and maximum ‘5’ for our sequence length, but it’s plausible to optimize
the results by tuning this parameter (falls under
future work
umbrella, discussed in later section).
Johannes (1998) [
8
] posits that using word sequences of length 2 or 3 are most useful for Reuters
news articles, and higher grams show negligible performance improvement, so we don’t expect
significant performance boost by tuning this parameter.
Running our classifier with preliminary n-gram model immediately performed better than fully
tuned feature extraction models implemented in preceding section (please see 5), with illustrative
performance improvement.
4.3 Sentiment Analysis and Intrinsic Evaluation
To validate our approach against previous work completed by Kazemian, Zhao, and Penn (2016)
and Pang and Lee (2004) our sentiment analyzer was examined on the movie review data set. Pang
and Lee’s (2004) movie reviews dataset contains 1000 positive and 1000 negative reviews. Data
preprocessing, feature selection and machine learning methods outlined in Section 3.1 and Section
4.1 were implemented on the movie reviews dataset as a sanity check. Data was prepossessed to
remove stop words, punctuation and, words with a length of one. An additional processing step
was completed to remove all words with a frequency of 3 or less in the training corpus. The feature
selection methods mentioned in Section 4.1 were employed with machine learning methods Naive
Bayes and Support Vector Machines with a linear kernel. The hyper-parameters for each model were
tuned with Grid Search and 10 fold cross validation. The optimal parameters found were an alpha
parameter of 1 for Naive Bayes and a regularization parameter of 1 for SVM using L2 penalty and
hinge loss. The classification accuracy reported in the Figure 3 is the average for model over 10 folds.
Stratified k-fold cross validation was used in order to preserve the percentage of a class in each fold,
to prevent bias in a sample.
The highest accuracy obtained was 87.4% using TF-IDF features and Support Vector Machines as
shown in Figure 3. Term Presence and BM25 features with Support Vector Machines also had a high
performance on the movie reviews dataset. The results obtained are comparable with Kazemian,
Zhao, and Penn (2016) accuracy of 86.85% and Pang and Lee (2004) accuracy of 86.4%. This shows
our our sentiment analyzer algorithm is a comparable approach to the previous work we are building
5

Figure 3: Average 10 fold cross validation accuracy on movie reviews dataset
on. This intrinsic evaluation validates our approach to training a sentiment analyzer using Support
Vector Machines and Feature Selection.
5 Demonstration
The sentiment analyzer was trained and tested on our combined final dataset of 19 stocks to explore
the relationship between the release of news and stock volatility. We also ran a generalization test on
the ‘credit card companies’ data set as outlined in Section 3.
Feature selection methods referenced in Section 4.1 and Section 4.2 were employed with machine
learning techniques Naive Bayes and Support Vector Machines using a linear kernel. The sentiment
classifiers were evaluated on training and test data separated with an 80-20 split. For the initial
evaluation, price volatility was calculated using closing stock price on the news release date and one
day following (using equation:
ln(
P
t
P
t−1
)). The sentiment of news was classified based on the price
volatility, with a positive value corresponding to a positive label and a negative value corresponding
to a negative label. In the initial experiment, zero was used as the threshold for negative and positive.
Figure 4 and Figure 5 shows the performance of the sentiment classifiers on the test sets. Feature
selection with NLTK had the highest accuracy and F1 score on the both datasets. Linear support
vector machines slightly outperformed the Naive Bayes classifier on the S&P500 dataset with an F1
score of 0.62 versus 0.60, the results for credit card company data had an even closer margin.
Figure 4: Test Accuracy (%) for the sentiment classifiers
Figure 5: F1 Score for the sentiment classifiers
To further analyze the performance of the sentiment classifiers positive and negative F1 scores are
examined in Figure 6. Feature selection with NLTK preformed the highest in terms of overall accuracy
and F1 score on both datasets, the improvement is attributed to an increase in the classification of
positive volatility and a slight decrease in the negative classification.
6

Figure 6: Positive and Negative F1 scores for the sentiment classifiers
Figure 7 displays the confusion matrix for the top performing classifier, the support vector machines
using feature selection with NLTK. The classifier has a higher accuracy when predicting the positive
class.
Figure 7: Normalized confusion matrix with SVM classification and Feature Selection using NLTK
The final experiment was to tune the price volatility formula with the most accurate classifier found in
the initial experiment. This was the SVM classifier using feature selection with NLTK on the credit
card company dataset. Stock price volatility was calculated using the formula outlined in Section
3.2. Figure 13 in Appendix B.2 displays the test accuracy for the price volatility calculation with the
parameter p between 0 and 5. P equal to 0 is the baseline condition and price volatility calculation
used in the initial experiment. The optimal value of p is found to be equal to 3, providing improved
test accuracy over the baseline from the initial experiment. Please see Figure 14 in Appendix B.2 for
complete ‘p’ parameter tuning results. The following Figure 8 shows the performance of the tuned
model:
Figure 8: Test results for the SVM classifier using NLTK n-gram features selection and p=3 for price
volatility formula on the credit card data set
The result of the SVM classifier with p tuned to 3 is displayed in 8. This outperformed all sentiment
classifiers in the initial experiment by a margin of 7.2%, the F1 score was improved by 0.6. The
classifier had an improved positive F1 score from 0.72 to 0.78 and the negative F1 score increased
from 0.49 to 0.57 with the tuning of the price volatility formula. The improved negative F1 score
improves the classification of "negative" results by a significant margin. As can be seen in Figure 9,
7
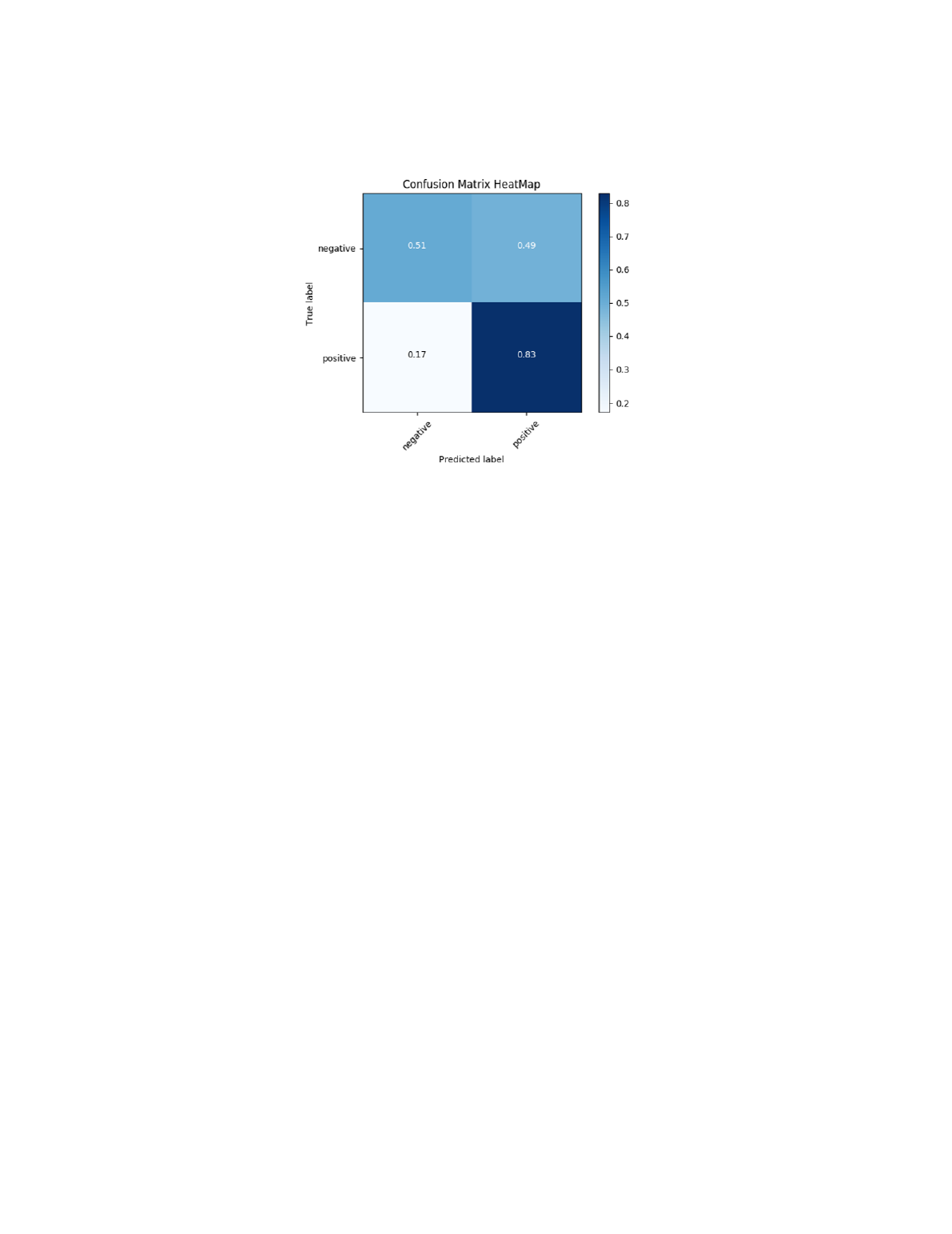
the classifier has better precision in predicting "positive" outcomes, a result consistent throughout the
experiment.
Figure 9: Normalized Confusion Matrix the SVM classifier using feature selection NLTK and p=3
for price volatility formula on the credit card data set
6 Limitations and Future Work
6.1 Limitations and Challenges
• Small training data set
: a limiting factor was the size of the dataset, 16,256 news articles contained
approximately 11,000 unique words. Providing accurate sentiment analysis prediction on future
articles requires a move in-depth understanding of language and a significantly larger training corpus.
• Impact attribution of news data on price volatility
: news data was extracted from Reuters,
however we know that not every news story published will occur in Reuters. Therefore, various other
sources that generate textual news data (like other news publications - e.g. Financial Post, financial
report filings, analyst reports, social media posts - e.g. Twitter, Facebook etc.) were ignored in our
experiments. Thus, by training our model using only one source of data is sure to introduce some
attribution bias. However, research modeling entails simplification, and using Reuters only data set,
in our opinion, is an acceptable proxy - as also validated by numerous other academic literature that
uses this same technique.
• Impact attribution of exogenous market factors on price volatility
: This is arguably the biggest
limitation of our experiments, and perhaps a major weakness of our technique overall. Stock price
volatility of an individual stock is not limited to news endogenous to itself, but multitude of exogenous
market factors: like industry specific events, overall macro- and socio-economic events. However, it is
our belief that such exogenous events, if pertinent enough to induce price volatility, would be covered
in news data (may be not in news specific to a company perhaps, but as part of overall industry news).
So, we can address that issue by refining news extraction and features selection techniques.
6.2 Future Extensions
• Evaluation of trading strategies using ‘PrivySense’
: due to imposed space constraint and time
limitation, we considered a detailed ‘task-based evaluation’ of PrivySense beyond the scope for the
first submission of this paper. However, we consider this to be imperative for the next version, as
it would allow us to empirically compare our model’s returns with other literature, including the
Kazemian’s paper where the model with best market returns had 3.46% 30-day returns with intrinsic
(sentiment) classification accuracy of approximately 62% (much lower than PrivySense) [9].
8
• Parametric tuning and optimization
: we have outlined the possibility of overall model perfor-
mance improvement in a few sections - where we haven’t tuned hyper-parameters. Most notably, for
our price volatility calculations, we did not tune and fit the GARCH(p, q) parameters for the ‘news
impact curve’. Also, the Engle and Ng (1993) paper offers other models (GJR and EGARCH) that
capture the news impact asymmetry of positive and negative news classes as better performers than
our simple GARCH(1,1) model. Thus, we would like to optimize our model selection in this regard.
We would also like to explore, incorporate and optimize advanced NLP techniques to better capture
semantic meaning from news data. For e.g., tune the grammar rules used for part of speech tagging
and word chunking. We expect high accuracy gains in this aspect as financial documents have domain
specific linguistic uniqueness in structure. For e.g., consider the linguistic similarity in quarterly
reports news or SEC filings across the S&P universe companies.
• Address limitations
: in the future, we would like to fix some of the limitations outlined in this
paper. For e.g., we would like to increase the size of our curated dataset for training our model.
This can be easily achieved by using our news crawler already implemented. For e.g., we would
like to train our classifiers using news documents of all NASDAQ listed companies and evaluate its
performance. Such large datasets would also increase the computation time significantly - and we
plan to address that by using distributed GPUs as our computation machine.
7 Conclusion
PrivySense
is a novel approach to evaluate sentiment in financial textual data. Using the proposed
technique, we infer sentiment in news data using price fluctuations of asset prices. We trained a
supervised support-vector-machine model that achieved 71.1% accuracy on generalized data set.
The idea for this experiment came from Kazemian, Zhao, and Penn’s (2016) paper which examined
the underlying sentiment analyzer in a trading strategy, finding the analyzer that performed highest
on market returns performed lowest on traditional sentiment score. The results of the paper has
sentiment classifiers performing between 62.09% and 81.14% when evaluated on human-subject
annotations [
9
]. The classification accuracy achieved in this experiment of 71.1% is within the range
of this study.
The disconnect between traditional sentiment and market reaction was further explored by evaluating
the news corpus with a high-quality traditional sentiment classifier. The Microsoft Azure Text
Analytics API was tested on the news data corpus to compare sentiment and stock price volatility.
The Microsoft text analytics sentiment score for the Reuters news corpus from 2015-2017 containing
randomly selected stocks from the S&P500 was compared against binary price volatility calculated
1-day after news release. The results were 52% accuracy for correctly predicting price volatility, with
positive sentiment corresponding to a positive price volatility and negative sentiment corresponding
to a negative price volatility. This result further illustrates the complex relationship between news
sentiment and market reaction. The failure of Microsoft API to explain price volatility shows the
need for exploring newer approaches to financial data sentiment analysis.
In this experiment, we have explored a new approach by establishing a relationship between price
volatility and the release of financial news directly gauging the market reaction with a task based
sentiment classifier. Future work would be to further evaluate the results achieved by utilizing this
sentiment analyzer in a trading strategy.
9
References
[1]
Sarkis Agaian and Petter Kolm. Financial sentiment analysis using machine learning techniques.
[2]
Roy Bar-Haim, Elad Dinur, Ronen Feldman, Moshe Fresko, and Guy Goldstein. Identifying and
following expert investors in stock microblogs. In Proceedings of the Conference on Empirical
Methods in Natural Language Processing, pages 1310–1319. Association for Computational
Linguistics, 2011.
[3]
Tim Bollerslev. Generalized autoregressive conditional heteroskedasticity. Journal of econo-
metrics, 31(3):307–327, 1986.
[4]
Hailiang Chen, Prabuddha De, Yu Hu, and Byoung-Hyoun Hwang. Wisdom of crowds: The
value of stock opinions transmitted through social media. The Review of Financial Studies,
27(5):1367–1403, 2014.
[5]
Ann Devitt and Khurshid Ahmad. Sentiment polarity identification in financial news: A
cohesion-based approach. In ACL, volume 7, pages 1–8, 2007.
[6]
Robert F Engle. Autoregressive conditional heteroscedasticity with estimates of the variance of
united kingdom inflation. Econometrica: Journal of the Econometric Society, pages 987–1007,
1982.
[7]
Robert F Engle and Victor K Ng. Measuring and testing the impact of news on volatility. The
journal of finance, 48(5):1749–1778, 1993.
[8]
Johannes Fürnkranz. A study using n-gram features for text categorization. Austrian Research
Institute for Artificial Intelligence, 3(1998):1–10, 1998.
[9]
Siavash Kazemian, Shunan Zhao, and Gerald Penn. Evaluating sentiment analysis in the context
of securities trading. In ACL (1), 2016.
[10]
Su Nam Kim, Timothy Baldwin, and Min-Yen Kan. Evaluating n-gram based evaluation metrics
for automatic keyphrase extraction. In Proceedings of the 23rd international conference on
computational linguistics, pages 572–580. Association for Computational Linguistics, 2010.
[11]
Moshe Koppel and Itai Shtrimberg. Good news or bad news? let the market decide. Computing
attitude and affect in text: Theory and applications, pages 297–301, 2006.
[12]
Bo Pang and Lillian Lee. A sentimental education: Sentiment analysis using subjectivity
summarization based on minimum cuts. In Proceedings of the 42nd annual meeting on
Association for Computational Linguistics, page 271. Association for Computational Linguistics,
2004.
[13]
Bo Pang, Lillian Lee, et al. Opinion mining and sentiment analysis. Foundations and Trends
R
in Information Retrieval, 2(1–2):1–135, 2008.
[14]
Juan Sixto, Aitor Almeida, and Diego López-de Ipiña. Improving the sentiment analysis process
of spanish tweets with bm25. In International Conference on Applications of Natural Language
to Information Systems, pages 285–291. Springer, 2016.
[15]
Timm O Sprenger, Andranik Tumasjan, Philipp G Sandner, and Isabell M Welpe. Tweets
and trades: The information content of stock microblogs. European Financial Management,
20(5):926–957, 2014.
[16]
Wenbin Zhang, Steven Skiena, et al. Trading strategies to exploit blog and news sentiment. In
Icwsm, 2010.
10

Appendices
A Methods and Materials
A.1 News Data
The following Figure 10 shows a sample snippet of news documents mined from Reuters news data
collection.
Figure 10: Sample news document mined from Reuters news data.
A.2 Prices Data
The following Figure 11 shows a sample snippet of prices csv file from WRDS research services
database.
Figure 11: CSV file snippet showing price data for AAPL.
B Price Volatility Calculation
B.1 News Impact Curve
The following Figure 12 shows the ’News Impact Curve’ [8] used for our volatility calculation as
was detailed in the methods section. The reason for including the curve for EGARCH(1,1) model
was to illustrate an important
limitation
of our used model GARCH(1,1). As can be seen from the
figure, the GARCH model assumes symmetric impact on volatility for both positive and negative
news, and doesn’t capture the asymmetric relationship, i.e. negative news having bigger impact on
price volatility relative to positive - as established by numerous research literatures in the domain
[French (1987), Nelson (1990)].
11

Figure 12: The news impact curves of the GARCH(1,1) model and the EGARCH(1,1) model.
B.2 Test Accuracy for Price Volatility Calculations
Figure 13: Test accuracy for SVM classifier with varying price volatility formula
12

Figure 14: SVM classifier test accuracy result with varying price volatility formula
C Multi-class labeling using thresholds
In essence this is filtering based on volatility ranking, keeping the more volatile samples and discarding
the lower vol samples, to allow for attribution for other exogenous market factors affecting the price
movement barring news. Instead of labeling the classes binary (positive or negative) based on
volatility sign, we create a neutral (safety zone) by using a ‘min-threshold’ and ‘max-threshold’
variable where the neutral class lies in the range: [min-threshold < 0 < max-threshold].
Evaluation of models using the feature selection methods mentioned in Section 4.1 were employed
with machine learning techniques Bernoulli Naive Bayes and Support Vector Machines using a linear
kernel. Initial evaluation was completed on 2015-2017 Reuters news data for 19 stocks from the
S&P500. Price volatility was calculated using closing price from news release date and one day
following. The dataset were divided by 80% and 20% train and test split.
As can be seen in Figure 15, the classifier has better precision in predicting ‘positive’.
Figure 15: Confusion matrix with 2 class SVM classification with N-gram words.
13
