
FILIP: Fine-Grained Interactive
Language-Image Pre-Training
Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang,
Zhenguo Li, Xin Jiang, Chunjing Xu
Presented by:
Anthony Bilic, Kunyang Li, David Shatwell, Zain Ulabedeen Farhat, Kevin Zhai
ICLR 2022 Poster (336 Citations)

Outline
1. Background/Motivation
2. Method
3. Results
4. Conclusion
5. Limitations

Background / Motivation

Problem
● CLIP is not able to capture fine-grained interactions
○ Uses global features (entire images and sentences)
○ Cannot capture relationship between image patches and textual words
● “... CLIP also struggles compared to task specific models on very fine-
grained classification, such as telling the difference between car models,
variants of aircraft, or flower species.” - OpenAI
Source: https://openai.com/research/clip

Previous Works in Learning Fine-Grained Interactions
Attention-based “Region-of-Interest”-based
a stone statue
Image encoder
dog sitting on couch
Transformer
Object Detector
● VisualBERT
● UNITER
● ALBEF
● ViLT
Text encoder
Attention

FILIP Main Contributions
● Overcomes previous issues using token-wise maximum similarity
● Prompt templates for downstream tasks
● Introduces several optimizations to reduce the training time
● Demonstrates improved zero-shot classification and I2T retrieval over CLIP

Method
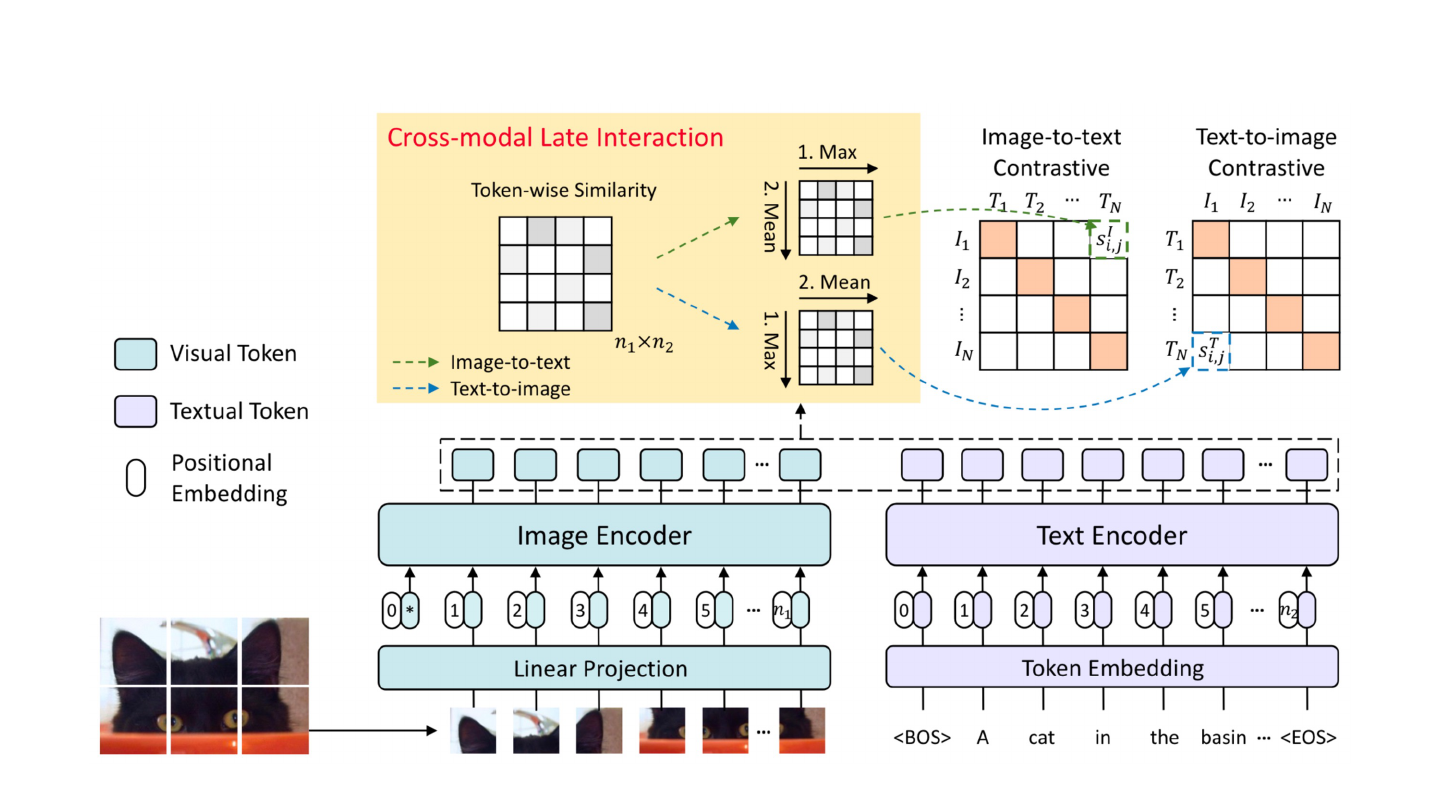
Overall architecture
Yao, Lewei, et al. FILIP: Fine-Grained Interactive Language-Image Pre-Training. arXiv:2111.07783, arXiv, 9 Nov. 2021. arXiv.org.

Cross-modal late interaction: image-to-text
<BOS> A
photo of a
white building
<EOS>
I
i
T
j
I
1
I
2
… I
N
T
1
T
2
…
T
N
Text-to-image
similarity
Cosine
Similarity
Token-wise similarity
between I
i
and T
j
…
…
max across
columns
mean across
rows
I
1
I
2
…
I
N
T
1
T
2
…
T
N
Batch image-to-
text
similarity
Batch text-to-
image
similarity

Cross-modal late interaction: text-to-image
I
1
I
2
…
I
N
T
1
T
2
…
T
N
Batch image-to-
text
similarity
mean across
columns
<BOS> A
photo of a
white building
<EOS>
Cosine
Similarity
I
i
T
j
…
…
Token-wise similarity
between I
i
and T
j
I
N
I
1
I
2
…
T
1
T
2
…
T
N
Batch text-to-
image
similarity
max across
rows

Loss function: contrastive loss
I
1
I
2
…
I
N
T
1
T
2
…
T
N
Image-to-text
similarity
I
1
I
2
… I
N
T
1
T
2
…
T
N
Text-to-image
similarity
+
… …

Dataset
FILIP300M
(300 million)
CC3M CC12M YFCC100M
+
Image-text
filters
Training dataset
FILIP340M
(~340M pairs)
Image filters:
● min(H,W) > 200 px
● aspect ratio < 3
Text filters:
● English
● Meaningful descriptions
● Repeated < 10 times
Open source
CC3M
(3 million)
CC12M
(~10 million)
YFCC100M
(~26 million)

Data Augmentation Methods for Pre-Training
Original [EN]: This is a photo of a nice house.
Translation [RU]: Это фото красивого дома.
Back-translation [EN]: This is a photo of a beautiful house.
Cubuk et al. AutoAugment: Learning Augmentation Strategies from Data. 2019
Image Augmentation Text Augmentation

Prompt Ensemble
Yao, Lewei, et al. FILIP: Fine-Grained Interactive Language-Image Pre-Training. arXiv:2111.07783, arXiv, 9 Nov. 2021. arXiv.org.
● “A photo of an {Audi 100 Sedan 1994}, a type of car. It’s important to me.”
● Also for CIFAR10, etc.
Dataset Prefix Category Suffix

FILIP Inference
“building”
“A photo of a building.
It’s common in daily life.”
Prompt
Ensemble
“A JPEG of a building, I
like it.”
…
Similarity
…
I
T
1
T
C
C = # prompt templates

Pre-Training Experimental Setup
● FILIP
base
uses VIT-B/32 → 128 Nvidia V100s, 9 days
● FILIP
large
uses VIT-L/14 → 192 Nvidia V100s, 24 days
Yao, Lewei, et al. FILIP: Fine-Grained Interactive Language-Image Pre-Training. arXiv:2111.07783, arXiv, 9 Nov. 2021. arXiv.org.

Pre-Training Experimental Setup
● Maximum # Text Tokens: 77
● Vocabulary Size: ~49k
● LAMB Optimizer
● Cosine Learning Rate Schedule + Linear Warmup
● Weight Decay → Training Stability
Yao, Lewei, et al. FILIP: Fine-Grained Interactive Language-Image Pre-Training. arXiv:2111.07783, arXiv, 9 Nov. 2021. arXiv.org.
For ablations

Pre-Training Efficiency
● FILIP determines similarity between tokens
● Reduced embedding size: 512 → 256
● Reduced precision in computing I2T and T2I similarities: fp32 → fp16
○ fp32: ~1.18e-38 … ~3.40e38 with 6–9 significant decimal digits precision
○ fp16: ~5.96e-8 … 65504 with 4 significant decimal digits precision

Pre-Training Efficiency
● Intuition: each sample can be represented by a few tokens
● Select 25% of tokens with the highest token-wise maximum similarity score
○ For both I2T and T2I similarities
Top 25% of {T
1
, … ,T
N
} for I
1
Top 25% of {T
1
, … ,T
N
} for I
2
Top 25% of {T
1
, … ,T
N
} for I
N
…
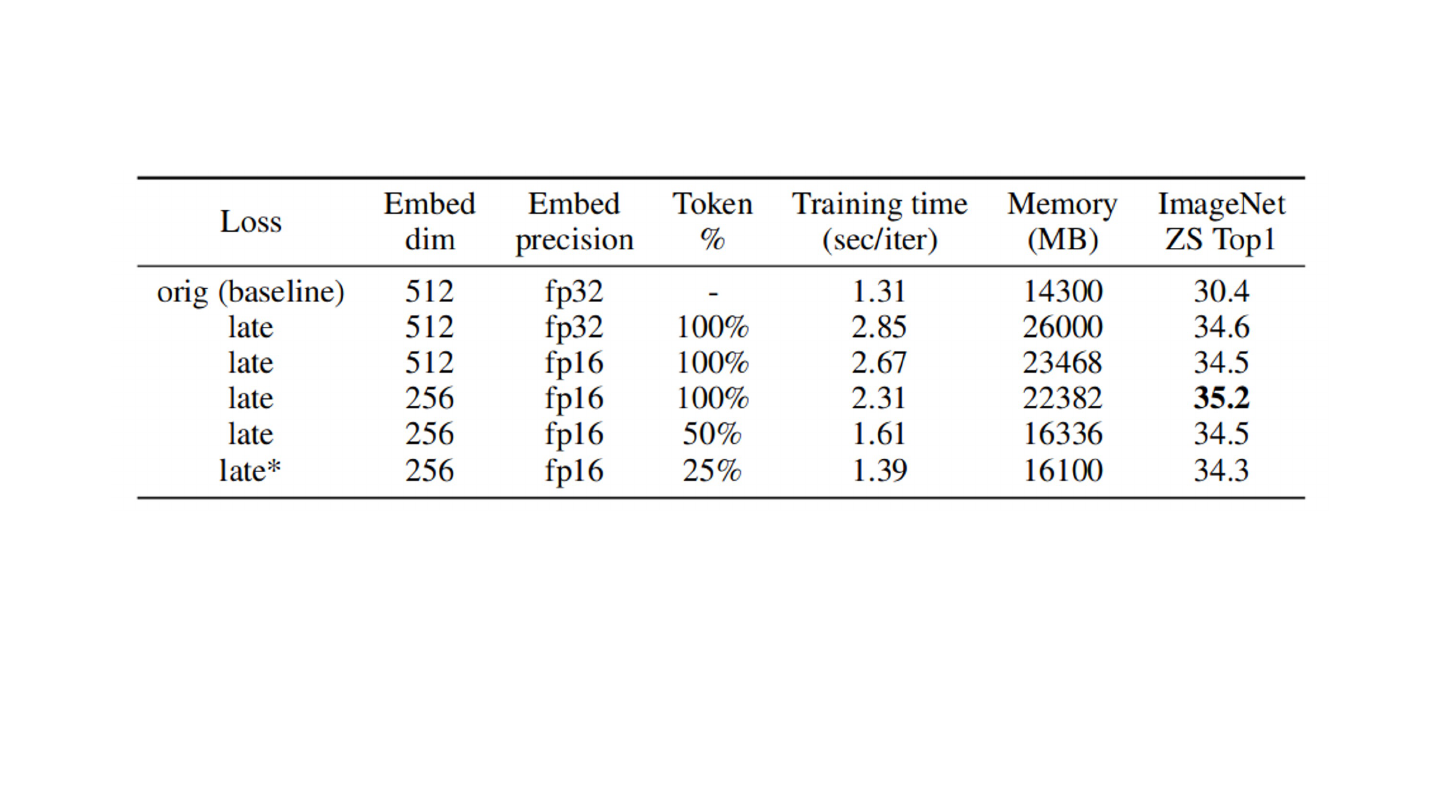
Effects of FILIP Model Optimizations
● * denotes final configuration (embed dim/precision, token %)
● 1.39 sec/iter vs 2.31 sec/iter
Yao, Lewei, et al. FILIP: Fine-Grained Interactive Language-Image Pre-Training. arXiv:2111.07783, arXiv, 9 Nov. 2021. arXiv.org.

I2T Retrieval Fine-Tuning Experimental Setup
Yao, Lewei, et al. FILIP: Fine-Grained Interactive Language-Image Pre-Training. arXiv:2111.07783, arXiv, 9 Nov. 2021. arXiv.org.
● For Flickr30K (30K pairs), MSCOCO (113K pairs)

Results

FILIP’s Evaluation Setting
● Evaluated with Zero-Shot Image Classification and Image-Text Retrieval
● Across many natural image datasets
Radford, Alec, et al. Learning Transferable Visual Models From Natural Language Supervision. 2021.
“[BOS] A photo of a bald eagle [EOS]”
0 1 2 3 4 5 6 7
“A photo of a {label}.”
“[BOS] A photo of a bullock cart [EOS]”
0 1 2 3 4 5 6 7

FILIP vs CLIP Zero-Shot Classification
● Evaluated on 12 downstream classification (augmented) datasets
● FILIP outperforms CLIP in average top-1 accuracy over 12 datasets
Yao, Lewei, et al. FILIP: Fine-Grained Interactive Language-Image Pre-Training. arXiv:2111.07783, arXiv, 9 Nov. 2021. arXiv.org, https://doi.org/10.48550/arXiv.2111.07783.

Domain-Specific Dataset Performance
● 30% increase in performance on the FGVCAircraft dataset
Radford, Alec, et al. Learning Transferable Visual Models From Natural Language Supervision. 2021

Image-Text Retrieval Results
● Tested on two retrieval benchmark datasets: Flickr30K and MSCOCO
● FILIP is 2.7% higher than ALIGN, which is trained on a 6x larger dataset
Yao, Lewei, et al. FILIP: Fine-Grained Interactive Language-Image Pre-Training. arXiv:2111.07783, arXiv, 9 Nov. 2021. arXiv.org.
* Denotes zero-shot results on Flickr30K after fine-tuning on MSCOCO

Image-Text Retrieval Ablations
● R@1 improvement of 5.5 % over vanilla CLIP ViT-B/32
● Effective in both Zero-Shot and fine-tuned Image-Text Retrieval tasks
Yao, Lewei, et al. FILIP: Fine-Grained Interactive Language-Image Pre-Training. arXiv:2111.07783, arXiv, 9 Nov. 2021. arXiv.org.

Word-Patch Alignment Visualizations
● Match images patches with captioned text tokens that have the highest similarity
Yao, Lewei, et al. FILIP: Fine-Grained Interactive Language-Image Pre-Training. arXiv:2111.07783, arXiv, 9 Nov. 2021. arXiv.org.

Conclusion
● FILIP ⇒ Fine-Grained Vision-Language Pre-Training Model
● Uses token-wise maximum similarity
● SoTA downstream tasks
● Later papers improve on the performance
○ E.g. BLIP-2

References
● [1] Radford, Alec, et al. "Learning transferable visual models from natural
language supervision." International conference on machine learning. PMLR,
2021.
● [2] Yao, Lewei, et al. "Filip: Fine-grained interactive language-image pre-
training." arXiv preprint arXiv:2111.07783 (2021).
